Replica project : status, issues and directions
The Replica project is the main target of my on-going PhD. It is quite an ambitious project of analyzing the millions of images present in Art Foundations around the world. The basis of such an analysis being the existence of Visual Links, which we define as a “visual correlation so strong that it can not be due to randomness” (i.e almost impossible two separate creators came with the same idea). Even without a formal definition, such connections have been used over the years by Art Historians to support conclusions such as authorship, pattern migrations, etc…

Examples of visual links
Status
In order to analyze this problem, we created a complete framework. We needed to acquire labelled data, but navigating a collection of images to make links between them is definitely outside of the scope of Amazon Mechanical Turk. So I developped our own web-application (using Angular), linking it with our servers (powered by Python).
The resulting system is a hybrid combination of the experimented approaches :
- Allows text searches using the metadata to navigate the collection.
- Allows variable image searches by using complex queries (as described in our DH2016 contribution)
- Allows detail matching, by using a simplification of this paper approach.
Without using the image search capabilities (to avoid acquisition biais), our amazing art-historian intern Carlotta (straight from University of Verona), managed during her stay to link more than 1’100+ works of art. This allowed us to try different image search algorithms, also showing that a significant performance gap can be achieved by training on this specific data (conclusions available in our last paper, EPFL Mirror).
The resulting work was a full-fledged search engine, allowing text queries, mulitple-images queries, and detail searches. It allowed us to get a much better understanding of the problem, and to gather our first dataset.
Limitations
However, the current system and approach does not allow us to go much further. I will detail here why a fondamental change to the architecture is needed.
Collections are complex and redundant
Until now, we were focusing only on the Web Gallery of Art dataset, because it was very comprehensive for our focus of study (Italian Renaissance). However, that assumed a very clean dataset, where one image has one metadata description and represents one object.
In practice, as soon as you gather multiple collections, duplicates appears everywhere (each collection having it’s own image of the most important masterpieces, but with slightly different lighting) ; metadata is conflicting ; multiple images may have been acquired for the same object ; …
We need a more flexible data model
The annotation process is not representative
Currently, the only “annotating” tool available to the user is creating a group out of multiple elements. This does not allow fine grained control, like individual pairwise linking-unlinking, and consider the “similarity-strength” of links with respect to others.
Also, the current system does not really allow multiple agents (users and/or bots) working together on the data acquisition/correction process.
Finally, we would want an annotation space which allows working at the big-picture level (not just between pairs), i.e in a graph edition manner.
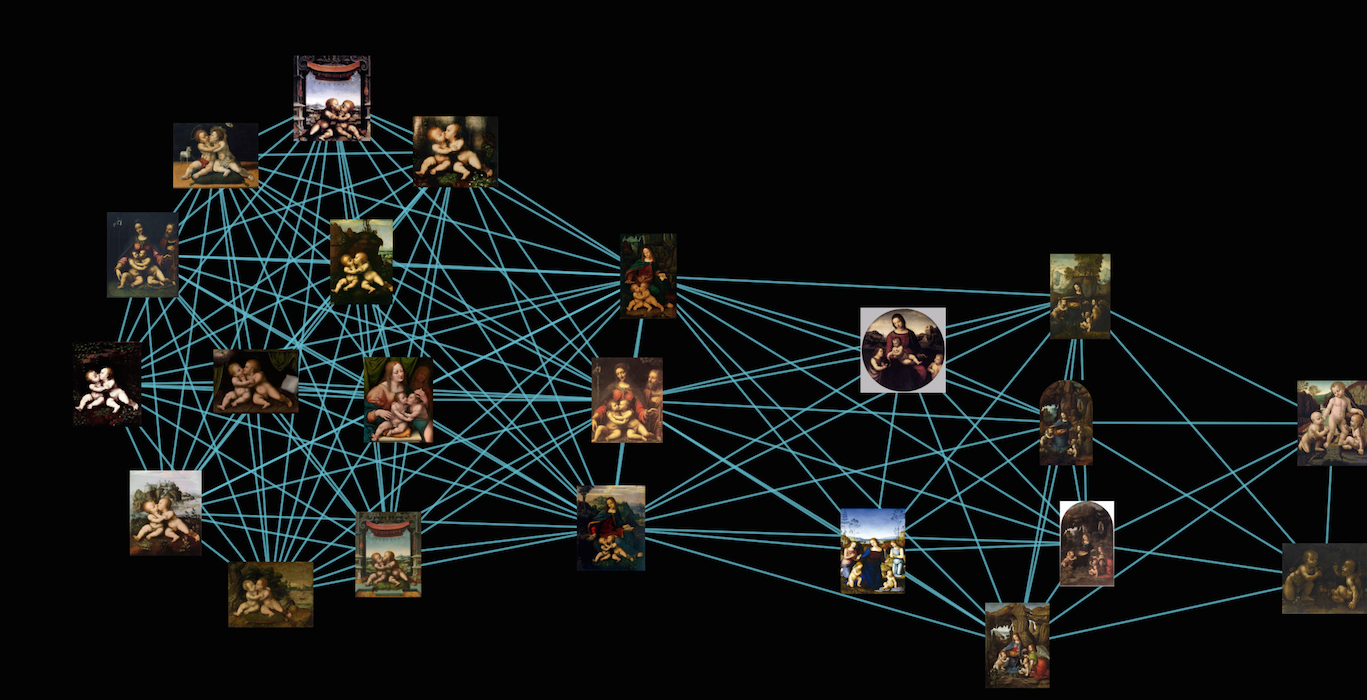
Prototype of a graph edition system
We need a better and crowd-sourcing enabling interface
The code is getting confusing
Because everything started small and features got added one-by-one, the code base would hugely benefit for a complete revamp. The system is using right now a mongodb database, a distributed task queue, two separate web services with rest api, a web-app front-end, a image-search service etc…
We need to better separate the system
Directions
In order to solve these multiple issues, I decided to refactor almost all the code base of the project implementing the following solutions.
Use the Europeana Data Model
The Europeana project has the difficult task of finding a way to make all the European collections interoperable with each others. They came up with the very precise Europeana Data Model (EDM) allowing very complicated dataset to be represented, and can be a very good basis for us a modelizing the fine grained relationships between them.
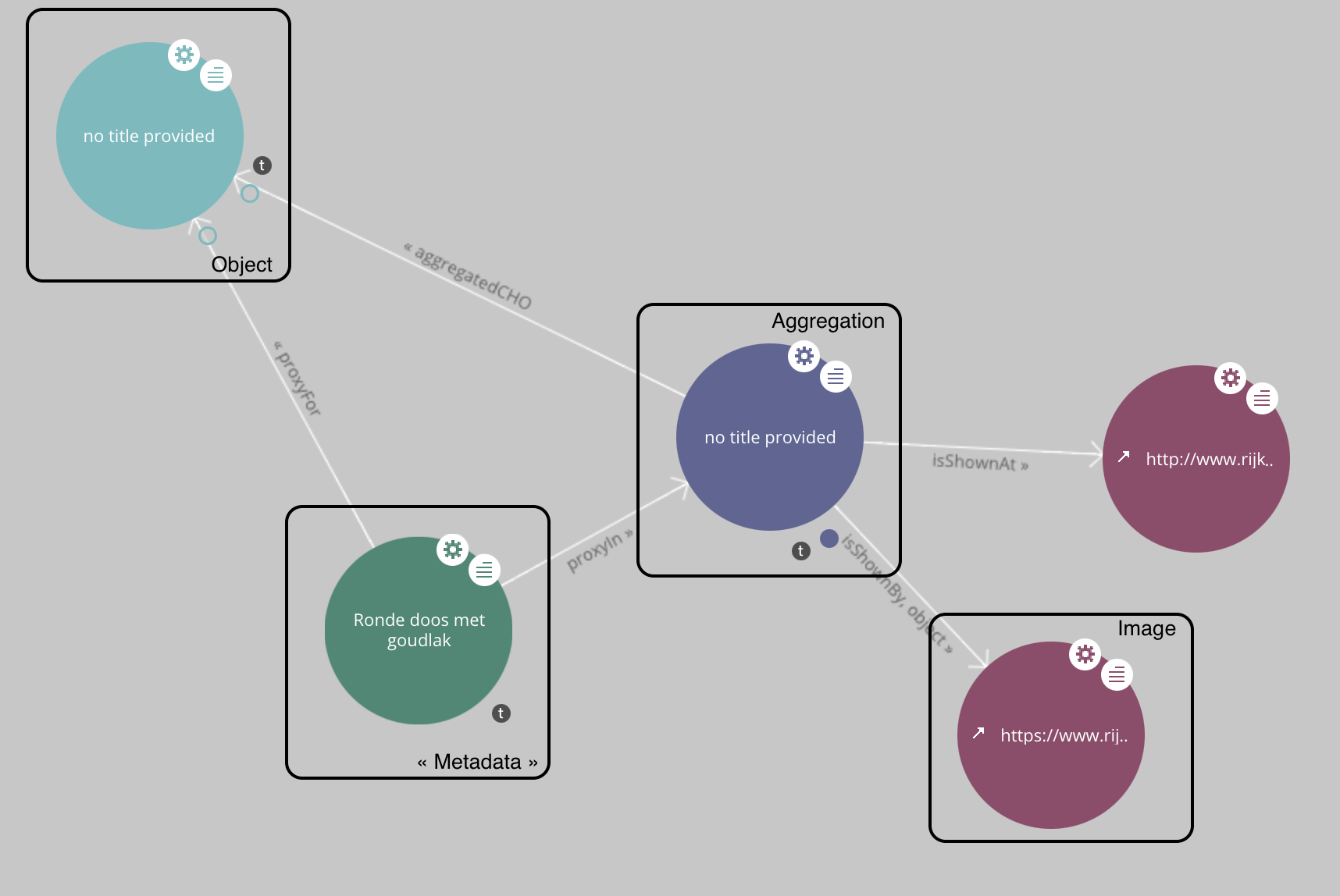
EDM data structure, extracted and annotated from a lodview exploration
Use the Web Annotation format, at the pairwise level
If we are planning to move to a RDF representation of the information, it also make sense to use the Web Annotation Data model. Such a system would allow us to keep track of who did what, whether it is a bot or a user. It would also allow for conflicting views by separate agents if necessary (a bot saying something different than an user for instance).
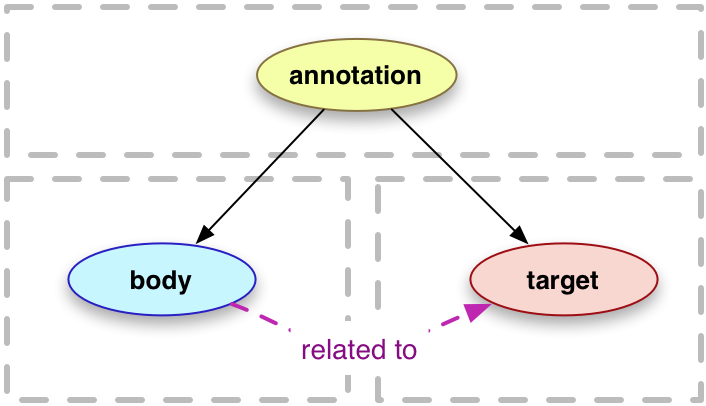
Web Annoation Model
A fundamental change as well, would be to record the information only between pairs of images, because we are dealing with links. Though in order to keep things efficient, that means having an interface adapted to these needs, allowing batch-operations, like adding or removing multiple pairs at the same time.
Which formalism to use in order to characterize the links is still the most obscure part of this rewriting (should it be between objetcs or images? Confidence level? Negative links? Same object or visually similar? What about almost indistinguishable engravings?).
Separate the project in sub-parts
In order to simplify the organization of the project, I decided to separate the projects in three parts :
-
Replica-core will contains most of the project logic in terms of representation of the information and its modification. It will only be accessible via a REST API.
-
Replica-search will only contains the image search and analysis capabilities. Even if Replica-core will depends on it, it could technically be independent.
-
Replica-webapp will be the front-end of the project, probably still in Angular and only interfacing with Replica-core through the REST API.
Also, along the course of this rewriting, I will probably publish the mature parts on github.
Conclusion
A lot of work ahead to get all of this working together, but I consider it an unavoidable path to be able to scale to the next dimension of this project.
I will probably write smaller posts along the way, describing more precisely parts of the process. No newline at end of file